스케일 넘치는 대용량 감사 로그, 스마트하게 관리하기 (OVEN)
2025년 1월 23일

서론
감사 로그(Audit Log)는 시스템의 보안, 투명성, 그리고 규정 준수 측면에서 중요한 역할을 합니다. 특히 금융, 의료, 공공기관과 같은 민감한 데이터를 다루는 분야에서는 감사 로그의 최소 보관 기간이 5년 이상으로 설정되는 경우가 많아, 적재 및 관리에 대한 요구가 더욱 중요해지고 있습니다. 예를 들어, 대형 금융 회사는 하루에도 수백만 건의 감사 로그가 생성되며, 이는 수년간의 보관 시 테라바이트(TB)가 넘는 큰 스토리지를 요구합니다. 이러한 대용량 로그 관리의 필요성은 날로 증가하고 있습니다.
문제
기존의 로그 관리 시스템은 다음과 같은 문제를 가지고 있습니다.
1. 저장 문제
로그 데이터가 지속적으로 증가하면서 데이터베이스 스토리지 확장이 필요하며, 이는 높은 운영 비용과 관리 복잡성을 초래합니다.
2. 조회 문제
대규모 로그 데이터를 빠르고 효율적으로 조회하기 어려워, 분석 및 규정 준수에 필요한 정보 추출이 지연될 수 있습니다.
3. 외부 연동의 비효율성
대용량 로그 데이터 효과적으로 분석하기 위해서는, 외부 OLAP 저장소에 적제하기 위한 ETL 추가 작업이 필요했습니다. 이러한 부가 작업은 개발 비용과 운영 부담을 증가시켰습니다.
솔루션
QueryPie 대용량 감사 로그를 효과적으로 저장, 조회 및 관리를 위해 아래 목표를 설정하였습니다.
1. 대용량 로그를 효율적으로 저장하기 위해, S3와 같은 오브젝트 저장소와 연동하여 로그 데이터를 저장합니다.
대용량 로그 데이터를 저장하기 위해서는, 오브젝트 저장소와 연동하여 로그 데이터를 저장하는 것이 효율적입니다.
2. 외부 연동의 효율을 높이기 위해 외부 S3에 적재된 데이터는 외부 OLAP 연동 및 조회가 용이한 형태로 저장합니다.
외부 OLAP 저장소에 적재하기 위해서는, 데이터를 적재하는 형태가 OLAP 저장소에 적합한 형태로 저장되어야 합니다.
3. 위 목표를 만족하기 위하여, 감사 로그 특성을 고려한 필요한 기능만 제공하여 불필요한 기능을 배제합니다.
감사 로그는 적재 후 수정 되지 않으며, 명시적인 삭제가 필요하지 않습니다.
저장 및 조회 기능만 제공합니다.
감사 로그는 시간 순서대로 적재 되며, 시간 범위 내에서 목록에 대한 조회 기능만 제공합니다.
상세 설명
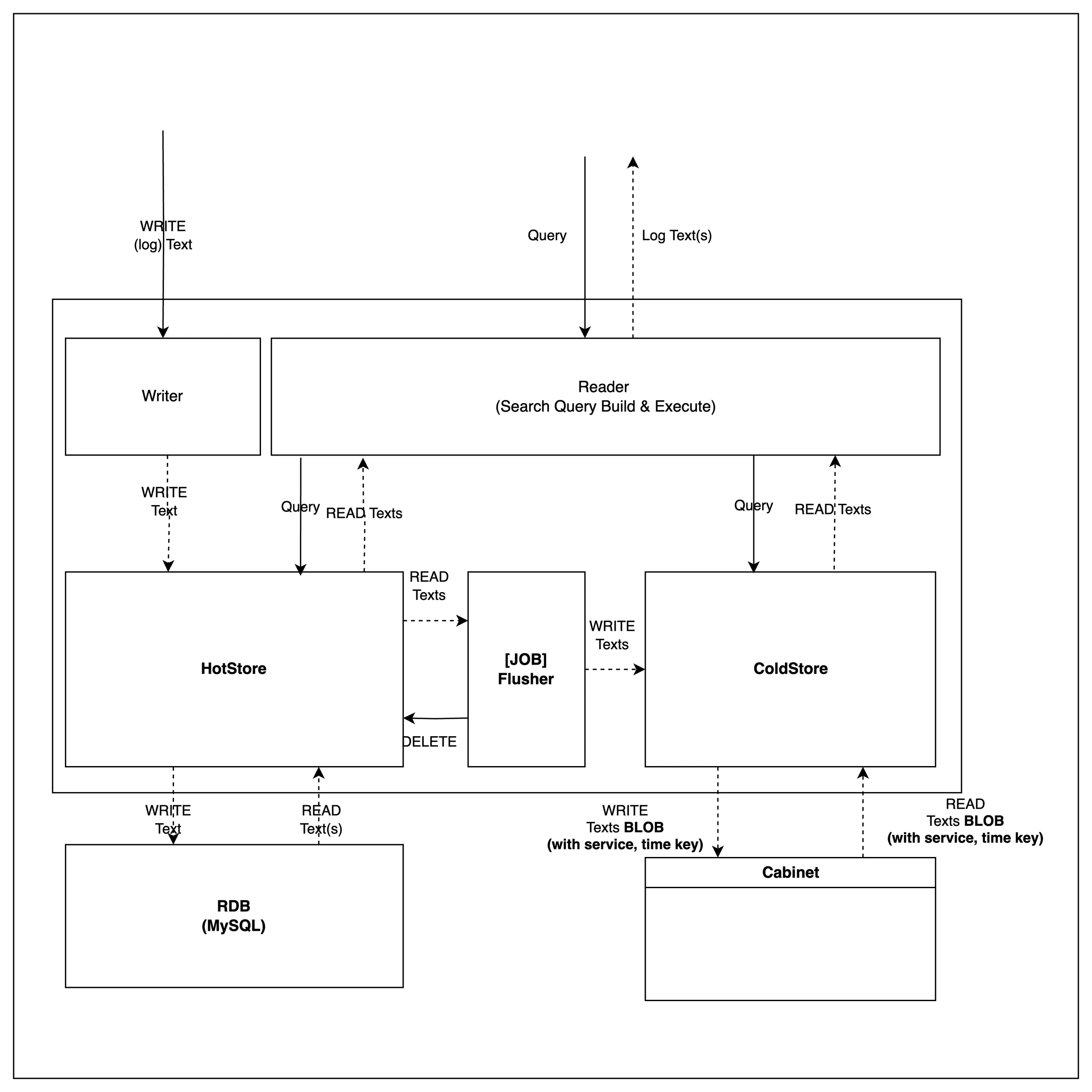
감사 로그 관리에 필요한 기능만 제공
감사 로그는 적재 후 수정되지 않으며, 명시적인 삭제가 필요하지 않습니다. 따라서, 저장 및 조회 기능만 제공합니다.
적재 (WRITE)
감사로그를 빠른 Write 성능을 가진 HotStore에 적재 합니다.
적재된 로그는 일정 기간이 지나면 ColdStore로 시간단위로 모아 이동합니다.
조회 (READ)
조회는 시간 범위 내에서 목록에 대한 조회 기능만 제공합니다.
내부 저장 공간과 무관한 일관된 조회 기능을 외부로 추상화하여 제공합니다.
대용량 로그를 효율적으로 저장하기 위해 BLOB 저장소와 연동
ColdStore로 이동된 로그는 내부 Cabinet Blob 저장소에 저장됩니다.
Cabinet은 Blob 저장소로 S3와 같은 오브젝트 저장소와 연동하여 로그 데이터를 저장합니다.
Blob 저장소에 저장된 감사로그는 WORM(Write Once Read Many) 특성을 가지고 있어, 적재된 로그 데이터를 수정하지 않고 조회만 가능합니다.
조회와 외부 연동을 위한 데이터 저장 형태
감사 로그는 로그 그룹명, 그리고 저장된 시계열 시간 정보가 가장 중요하고 조회시 필수 정보입니다.
대용량 로그 데이터 저장 조회시 일반적으로 사용되는 경로 기반 Partitioning을 사용해 조회 및 외부 연동을 용이 하게 합니다
collection=${COLLECTION}/date=${DATE}{HOUR}.gz로그 그룹명
${COLLECTION}
시간
${DATE}: Date of log storage.
${HOUR}: Hour of log storage.
예시
collection test-log
Logs from 2024-01-01T19:00:00 to 2024-01-02T01:00:00 (UTC) are stored as:
Collection | Date | Hour |
|---|---|---|
collection=test-log/ | date=2024-01-02/ | 01.gz |
02.gz | ||
date=2024-01-01/ | 23.gz | |
22.gz | ||
21.gz | ||
20.gz | ||
19.gz |
위 경로 기반 Partitioning은 외부 OLAP 저장소와 연동하여 로그 데이터를 조회하기 위한 효율적인 방법입니다.
아래 Athena를 사용하여 S3에 저장된 Diary 로그를 바로 조회 & 분석 가능한 예시를 제공합니다.
Athena 연동 및 조회 Example
S3 저장된 Diary 로그 Athena 연동 테이블 생성 예시
CREATE EXTERNAL TABLE test_log ( `record_uuid` STRING, `created_at` STRING, `data` STRUCT< msg: STRING, time: STRING, level: STRING, request_id: STRING, operation_id: STRING > ) PARTITIONED BY ( `date_created` STRING ) ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://${S3_BUCKET_ROOT_PATH}/collection=test-log/' TBLPROPERTIES ( 'classification' = 'json', 'compressionType' = 'gzip', 'projection.enabled' = 'true', 'projection.date_created.type' = 'date', 'projection.date_created.format' = 'yyyy-MM-dd', 'projection.date_created.interval' = '1', 'projection.date_created.interval.unit' = 'DAYS', 'projection.date_created.range' = '2024-12-01, NOW', 'storage.location.template' = 's3://${S3_BUCKET_ROOT_PATH}/collection=test-log/date=${date_created}/' ); 
