さまざまなベンダーのSQL解析のためのコア技術、QSI(Query Structural Interface)
2024年11月22日

序文
CCPA、GDPR、ISO 27001といったグローバルコンプライアンスを遵守する必要がある企業が、世界的に急増しています。このようなビジネス環境の変化により、一貫したデータ管理とセキュリティが企業活動の必須要素として浮上している傾向があります。実際に、データベースシステムは多様なプラットフォームとクエリ言語を介してアクセスされることが一般的ですが、データベースごとに文法や動作が異なるため、一貫したアクセス制御とモニタリングを行うのは非常に困難な問題です。そこで今回は、複数のデータベースのクエリを単一の抽象構文に統合し、リアルタイム分析を通じてデータベースクエリセキュリティの基盤を提供するソリューションをご紹介します。
Step.1 問題の発見: 多様なデータベースの文法の違いが管理の複雑さを引き起こす!
大規模企業やデータ中心の組織では、MySQL、SQL Server、PostgreSQL、Oracleといった従来のSQLデータベースだけでなく、MongoDBのような NoSQLデータベースも同時に使用しています。しかし、データベースごとにクエリの文法や動作が異なるため、同一のセキュリティポリシーを一貫して適用するのは容易ではありません。特に、データベースが拡張され、複雑化するにつれて、クエリの制御とセキュリティ管理の難易度が高まり、最終的には潜在的なセキュリティ脅威につながる可能性があります。このような複雑性は、GDPRやCCPAのような個人情報保護規制の要件を満たす際の障害にもなります。
以下は、データベースごとに行数を制限するクエリの例です:
MySQL
SELECT * FROM {table} LIMIT 10
SQL Server
SELECT TOP 10 * FROM {table}
Oracle
SELECT * FROM {table} FETCH FIRST 10 ROWS ONLY
MongoDB
db.getCollection('{table}').limit(10);
だからこそ、データベースクエリの制御が重要です。
今日のデータ漏洩事故の半数以上は、内部の脅威や不適切なアクセス制御に起因しています。例えば、一部の権限のないユーザーが高度な権限を必要とするデータを閲覧しようとした場合、従来のアクセス制御システムではこれを効果的に遮断することが困難です。クエリアクセスを適切に管理しないと、データ漏洩や悪意ある使用が発生する可能性が高まります。特に、データを直接扱う従業員やアナリストが機密データを含む大規模なクエリを実行する場合、その結果を予測するのは困難です。このような事態は、企業の重要な資産であるデータを、高い損失リスクにさらすことにほかなりません。
Step 2. 目標の設定: グローバルコンプライアンス要件を満たすソリューションを探せ!
これらの問題を解決するには、多様なデータベースに対して一貫したセキュリティポリシーを適用できる技術が必要です。この技術は、ISO 27001の情報セキュリティ管理システムの実装や、GDPRやCCPAで求められるデータ保護および個人情報管理の基盤となります。QueryPieは、これらのグローバルコンプライアンス要件を満たすための基盤技術について深く考えました。
一貫したセキュリティポリシー適用のためのQueryPieの3つの主要なアプローチ
多様なデータベースに一貫したセキュリティポリシーを適用するために、以下の3つの主要なアプローチを提案します。
多様なデータベースクエリのAST統合: MySQL、SQL Server、Oracle、MongoDBなど、多様なデータベースのクエリ文法を単一の抽象構文木(Abstract Syntax Tree, AST)に統合します。これにより、異なるデータベースのクエリを一貫して処理および分析することが可能になります。
リアルタイムクエリ分析と結果予測: ASTをリアルタイムで分析しながら、データベースのスキーマ情報を参照してクエリの実行結果を予測します。これにより、ユーザーやアプリケーションが実行するクエリの影響範囲を事前に把握することができます。
オブジェクト間の関係の精密な分析: クエリに含まれるテーブルやカラムなど、データベースオブジェクト間の関係を詳細に分析します。これにより、データフローを追跡し、機密データへのアクセスを効果的に検出して内部脅威を防止します。
技術的説明
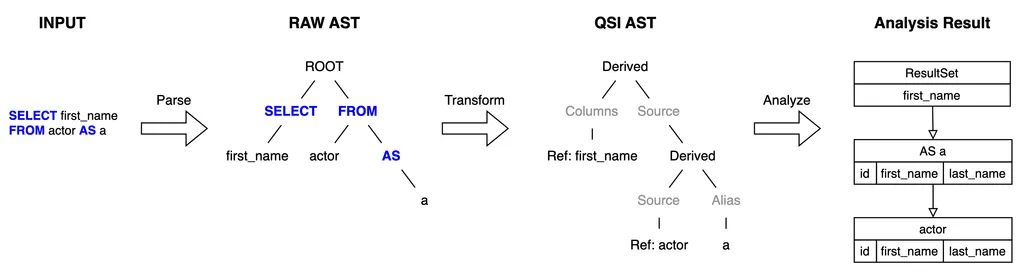
実行段階
実行プロセスは以下の 4つの段階に分類されます:INPUT、 RAW AST、 QSI AST、 Analysis Result
まず、INPUT段階では、クエリを受け取り、RAW AST(抽象構文木)にパースして構文構造を把握します。
次に、QSI AST段階で構文木を意味的構文木に変換し、各クエリ要素間の論理的関係を定義します。
最後に、Analysis Result 段階では、分析された情報を基に最終結果を生成し、クエリ結果がどのように構成されるかを予測するモデルを提供します。
INPUT
データベースクエリが原文のまま入力されます。
SELECT * FROM sakila.actorRAW AST
RAW ASTは、入力されたデータベースクエリをパースした際に、基礎的なパーサーが出力する結果を指します。
基礎的なパーサーは、ANTLR、YACC、JavaCCなどのよく知られたパーサージェネレーターを使用して実装されており、これによりデータベースごとに構文構造を分析したAST(抽象構文木)の結果が異なる可能性があります。同じパーサージェネレーターを使用していても、文法が異なる場合、MySQLのSELECT 1クエリとOracleのSELECT 1 FROM DUALクエリが意味的に等しいことを認識することはできません。
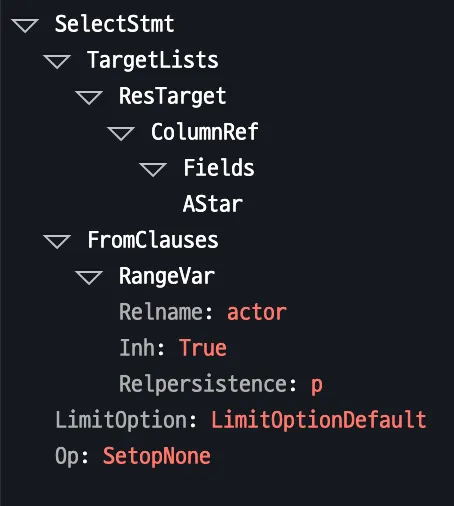
データベースごとのSELECT * FROM actorの例:
MySQL (ANTLR4)

Oracle (ANTLR4)
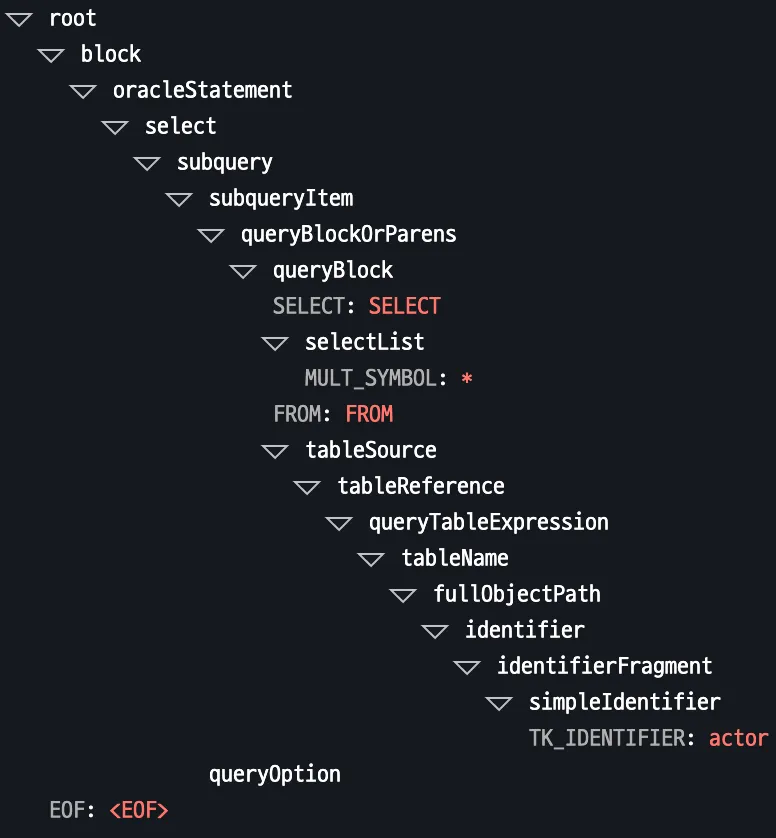
PostgreSQL (YACC)
QSI AST
QSI ASTは、データベースクエリの意味的構造を表現します。主に派生(Derivation)、結合(JOIN)、元データ(Source)を通じてデータ加工の過程を表し、さまざまなデータ処理演算を構造化します。以下に各要素の説明を示します。

